Hello everyone. I have 10 RUT241 devices, all connected via a 4G LTE connection to an OpenVPN server. Although I’m able to ping between peers, I encounter an issue when I try to access the Web User Interface (WebUI). It displays a message stating, “The device is unreachable. Please check the connection and try again.” I’ve attached the ping results between the PC and the router’s IP on the VPN, the output from logread -f, and the developer options for the /login page.
I’m at a loss as to what might be causing this issue and how to rectify it. This problem persists on 6 out of the 10 routers, with the remaining 4 operating flawlessly. I have SSH access, and the WebUI works seamlessly through a backup ZeroTier VPN.I have rebooted all just in case.
If anyone has insights on what could be going wrong or any potential solutions to this problem, I would greatly appreciate your assistance.

Hello,
The “Device is unreachable” message could be caused by a very unstable connection. Can you verify that the LAN clients are reachable without any issues?
Alternatively, there could be an issue with the OpenVPN configuration. Perhaps there are some route conflicts where the networks are overlapping? If possible, I will ask you to share a partial .ovpn configuration file. Log into the router using CLI - Command Line Interfaces RutOS - Teltonika Networks Wiki, and run the command cat /etc/config/openvpn. Copy only the portion above the certificates, and do not include any sensitive information like IP addresses. An example could could look like so:
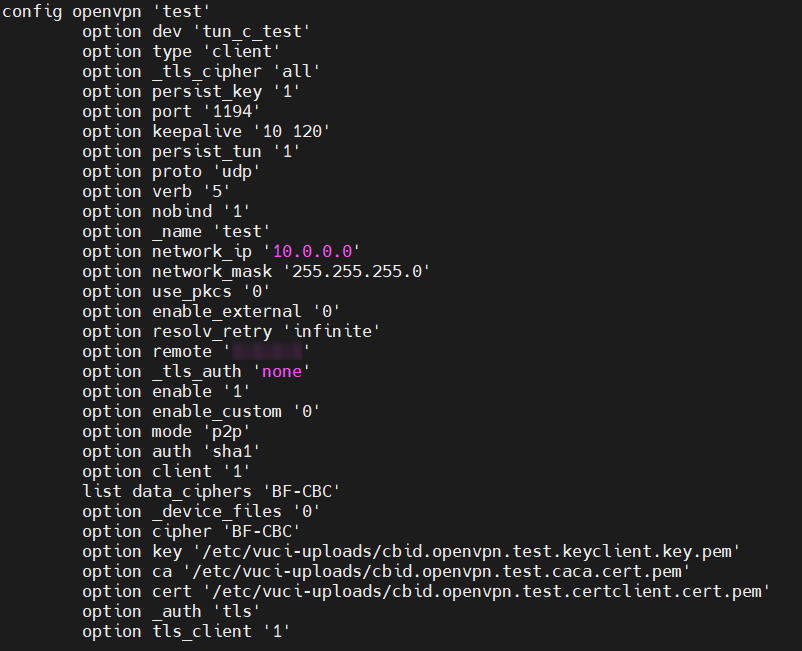
Best regards,
Hi! Thanks for the reply! Here are my OpenVPN config:
OpenVPN version:OpenVPN 2.5.5
Server.conf
port 1194
proto udp
mode server
tls-server
topology subnet
server 10.8.0.0 255.255.254.0
#client-to-client
persist-key
persist-tun
ca ecc/ca.crt
cert ecc/ca.crt
crl-verify ecc/crl.pem
dh none
key ecc/private.key
dev tun0
keepalive 10 240
cipher AES-128-GCM
tls-auth ecc/ta.key 0
tls-version-min 1.2
data-ciphers AES-128-GCM:AES-256-CBC:AES-256-GCM:CHACHA20-POLY1305
client-config-dir ccd
ccd-exclusive
log /var/log/openvpn/server.log
push "route 10.8.0.0 255.255.254.0"
#########StartRoutes######################
route 172.16.1.0 255.255.255.248
route 172.16.1.8 255.255.255.248
route 172.16.1.16 255.255.255.248
route 172.16.1.24 255.255.255.248
route 172.16.1.32 255.255.255.248
route 172.16.1.40 255.255.255.248
route 172.16.1.48 255.255.255.248
route 172.16.1.56 255.255.255.248
route 172.16.1.64 255.255.255.248
route 172.16.1.72 255.255.255.248
route 172.16.1.112 255.255.255.248
route 172.16.1.120 255.255.255.248
route 172.16.1.128 255.255.255.248
route 172.16.1.136 255.255.255.248
route 172.16.1.144 255.255.255.248
route 172.16.1.152 255.255.255.248
route 172.16.1.160 255.255.255.248
#########ENDRoutes######################
verb 3
user nobody
group nogroup
Client .ovpn
client
dev tun
proto udp
port 1194
remote XX.XX.XX.XX
remote-cert-tls server
resolv-retry infinite
nobind
persist-key
persist-tun
cipher AES-128-GCM
tls-version-min 1.2
tls-cipher TLS-DHE-RSA-WITH-AES-256-GCM-SHA384
key-direction 1
verb 3
<ca>
-----BEGIN CERTIFICATE-----
-----END CERTIFICATE-----
</ca>
<cert>
-----BEGIN CERTIFICATE-----
-----END CERTIFICATE-----
</cert>
<key>
-----BEGIN PRIVATE KEY-----
-----END PRIVATE KEY-----
</key>
<tls-auth>
-----BEGIN OpenVPN Static key V1-----
-----END OpenVPN Static key V1-----
</tls-auth>
CCD client file(example, each client has the same estructure)
ifconfig-push 10.8.0.5 255.255.254.0
iroute 172.16.1.0 255.255.255.248
Kind regards
Thank you.
Can’t see anything that could be causing issues right away. Perhaps it would be possible to gather logs from the RUT2 after replicating the issue? This can be done by running the command logread | grep openvpn. Make sure to remove any sensitive information.
Additionally, could you try pinging the RUT2 after not being able to access the WebUI and check if it responds and what is the latency?
Best regards,
Hi! I made the logread | grep openvpn, all seems fine for this part:
Tue Jul 18 21:39:25 2023 daemon.notice openvpn(VPN_Main)[17797]: VERIFY OK: depth=1, CN=Main CA
Tue Jul 18 21:39:25 2023 daemon.notice openvpn(VPN_Main)[17797]: VERIFY KU OK
Tue Jul 18 21:39:25 2023 daemon.notice openvpn(VPN_Main)[17797]: Validating certificate extended key usage
Tue Jul 18 21:39:25 2023 daemon.notice openvpn(VPN_Main)[17797]: ++ Certificate has EKU (str) TLS Web Server Authentication, expects TLS Web Server Authentication
Tue Jul 18 21:39:25 2023 daemon.notice openvpn(VPN_Main)[17797]: VERIFY EKU OK
Tue Jul 18 21:39:25 2023 daemon.notice openvpn(VPN_Main)[17797]: VERIFY OK: depth=0, CN=remoto
Tue Jul 18 21:39:25 2023 daemon.notice openvpn(VPN_Main)[17797]: Outgoing Data Channel: Cipher 'AES-128-GCM' initialized with 128 bit key
Tue Jul 18 21:39:25 2023 daemon.notice openvpn(VPN_Main)[17797]: Incoming Data Channel: Cipher 'AES-128-GCM' initialized with 128 bit key
Tue Jul 18 21:39:25 2023 daemon.notice openvpn(VPN_Main)[17797]: Control Channel: TLSv1.3, cipher TLSv1.3 TLS_AES_256_GCM_SHA384, peer certificate: 256 bit EC, curve prime256v1, signature: ecdsa-with-SHA512
I made a logread -f while trying to sign in multiple times:
Tue Jul 18 22:11:00 2023 kern.notice Authentication was successful from HTTP 10.8.0.3
Tue Jul 18 22:11:00 2023 daemon.err uhttpd[2144]: vuci: accepted login for admin from 10.8.0.3
Tue Jul 18 22:11:10 2023 kern.notice Authentication was successful from HTTP 10.8.0.3
Tue Jul 18 22:11:10 2023 daemon.err uhttpd[2144]: vuci: accepted login for admin from 10.8.0.3
Tue Jul 18 22:11:22 2023 kern.notice Authentication was successful from HTTP 10.8.0.3
Tue Jul 18 22:11:22 2023 daemon.err uhttpd[2144]: vuci: accepted login for admin from 10.8.0.3
Tue Jul 18 22:11:28 2023 kern.notice Authentication was successful from HTTP 10.8.0.3
Tue Jul 18 22:11:28 2023 daemon.err uhttpd[2144]: vuci: accepted login for admin from 10.8.0.3
The stranger part I think that is it:
daemon.err uhttpd[2144]
Say error, but it tell accepted login
I attach some pictures of ping while trying to access WebUI, and traceroute for both ends:
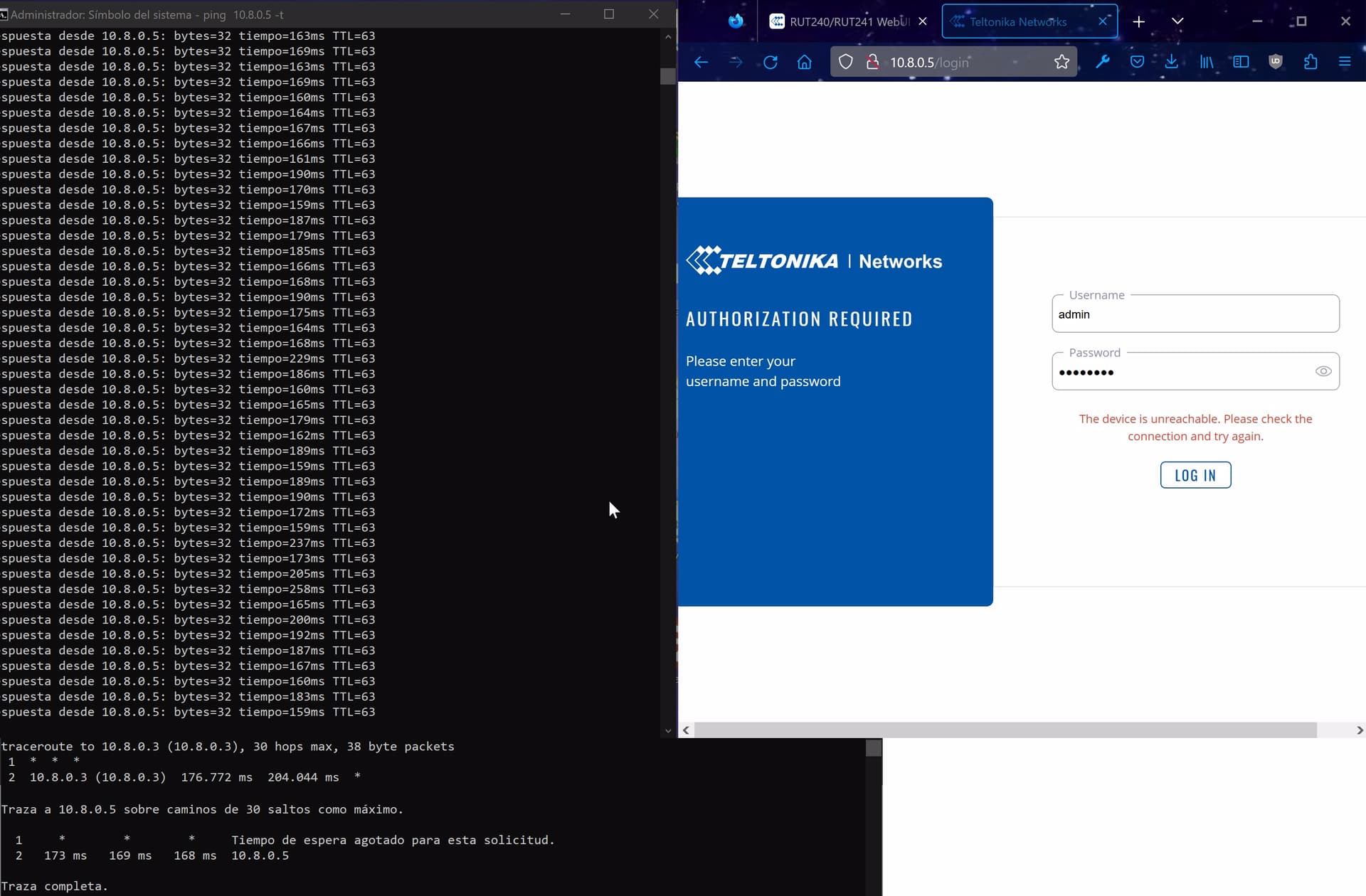
I think the only “stranger” thing is the daemon.err, and the latency, but I always have around 170ms of ping time, with spikes of 200ms,but the connection seems stable, in 10 minutes no ping lost,it´s too much ping for the webUI?If you have any other tests or things that I can accomplish, please feel free to reply!
Kind regards
One more thing that may help is lowering the MTU of the mobile interface. Please try editing the /etc/config/network config file, and under the config interface 'mob1s1a1' option change the option mtu '1500' to option mtu '1420'. Then execute a command /etc/init.d/network restart. It may take some time for the device to come back up. Let me know if this helps.
Have you tried changing the MTU value?
Best regards,
Hi! I will change later, we are in another proyects! Changing the MTU can make the router without Internet?, It is on a remote site and poorly accesible
Kind regards
No, changing the MTU will only temporarily break the internet connection (up to ~1 minute). It should recover afterward. Let me know if that helps.
Hi! I have changed MTU to 1420 and the problem seems to be here again, didn´t solved!
Kind regards
I think it is simpler to just delete the “option mtu ‘1500’” line and let the device negotiate the mtu of mob1s(x)a1 interface instead of setting a value which may change if the mobile operator reconfigure something in the network.
Currently the tower I am connected to cycles between 1500, 1420 and 1416 at random.
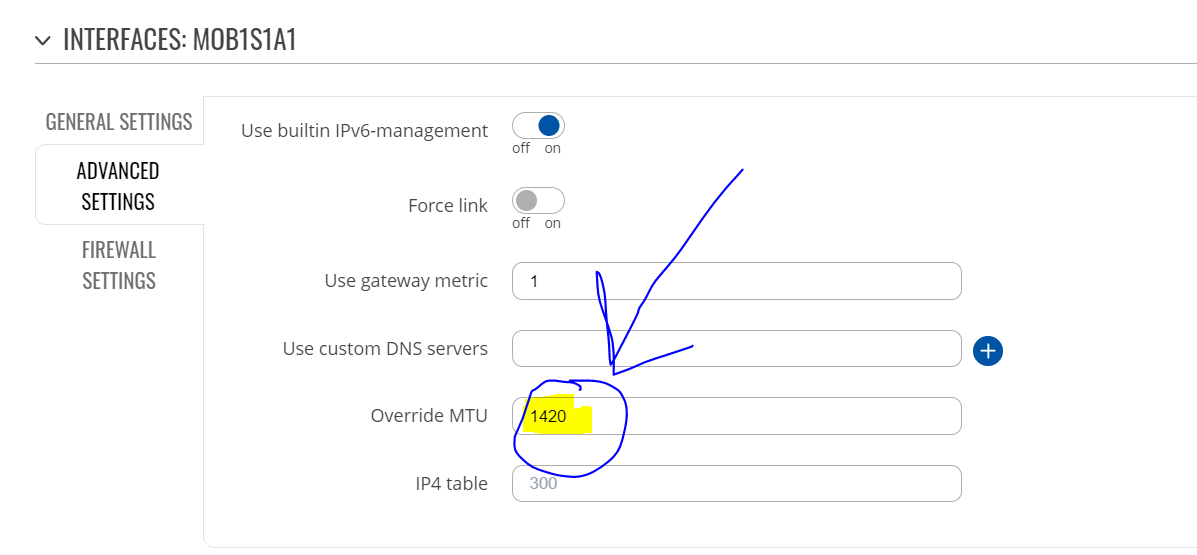
Yes, this is correct. Clearing the field will do the same.
It is a workaround for the carrier aggregation case, where two or more sub-carriers have a different MTU. Currently I have:
root@lgr5g:~# gsmctl -A 'AT+QMTUINFO'
+QMTUINFO: 1,1416,1416
+QMTUINFO: 2,1500,1280
So I have to force a value of 1416 because the negotiation may select the second value depending on the completion order in the establishment phase.
I’m pleased to share that I’ve managed to resolve the issue I was experiencing, which involved adjusting the Maximum Transmission Unit (MTU) of my mobile interface.
Previously, my MTU was set to 1420. However, after altering this setting to 1270, the problem appears to have been rectified. To ensure this configuration was optimal, I ran several ping tests using a specified packet size (using the command: ping -l 1270 10.8.0.1). I repeated this process until the tests were successful, thus verifying that the adjusted setting was appropriate for my case.
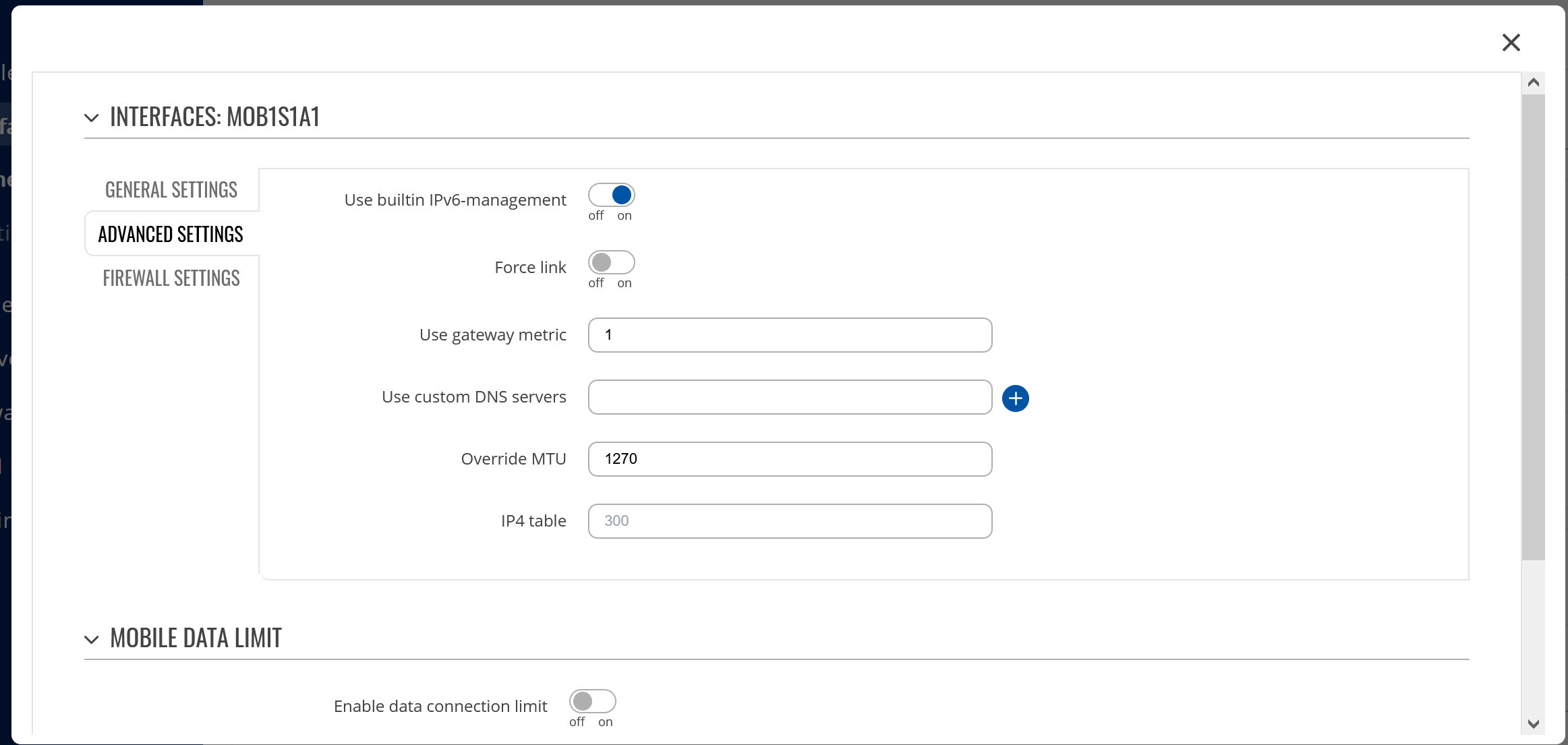
As of the moment, everything is working fine. I hope this information proves useful for anyone who might be encountering similar issues.
Best Regards.